

Imagine you hire the most brilliant person alive. They can write code, compose poetry, debug your entire infrastructure in one sitting. There is only one problem: every ninety minutes, someone walks into the room and erases their whiteboard.
Not metaphorically. Literally. Everything they were working on, everything you told them about yourself, every decision you made together—gone. They turn to you with a polite, vacant smile and say, “Hello! How can I help you today?”
This is the reality of every large language model. In the previous issue, we talked about giving the agent a memory file. Today, we need to talk about the brutal engineering required to maintain it.
Most developers try to solve this by just shoving more text into the prompt until the model crashes. OpenClaw took a different approach. It built the AI equivalent of an Operating System kernel. To understand why, you need to understand the problem first. And the problem is more interesting than you think.
The Suitcase Problem
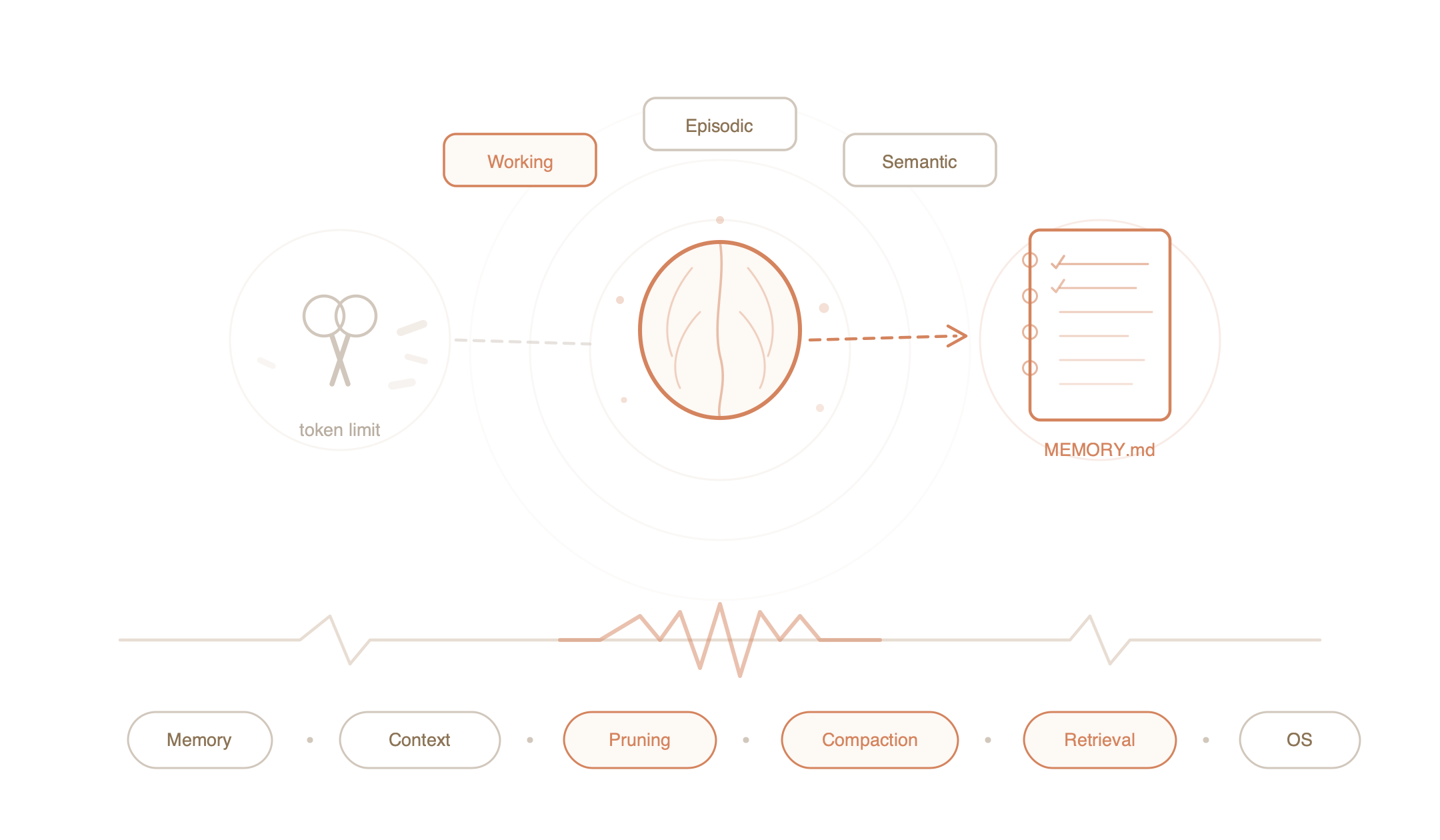
The word “memory” is a suitcase word—a single word stuffed with several completely different things. When someone says “the AI remembers,” they could mean three entirely separate phenomena, and conflating them is where most people get confused.
So let’s unpack the suitcase.
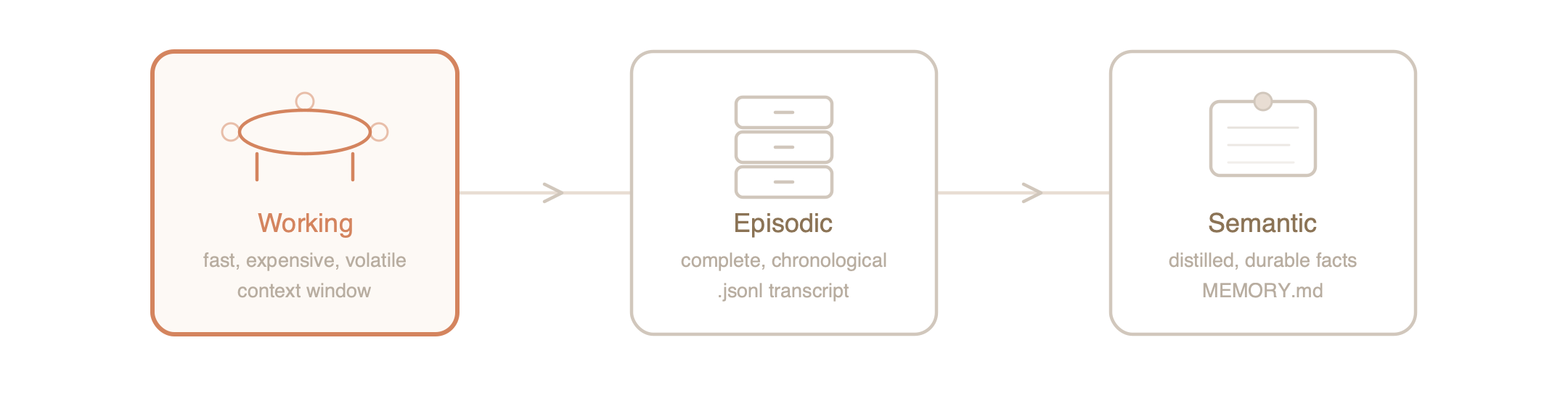
Working Memory is the conversation happening right now. It is what the model can see, think about, and respond to in this very moment. In technical terms, it is the context window—a fixed number of tokens the model holds in its attention mechanism at once.
Here is the thing nobody tells you about working memory: it is absurdly expensive. Every token in that window participates in every computation the model performs. Doubling the context doesn’t just cost twice as much; the computational cost scales quadratically. The context window isn’t a warehouse. It’s a conference table in a Michelin-star restaurant, and you are paying per seat per second.
Episodic Memory is the full record of everything that happened. Every message you sent, every tool the AI called, every result it received—stored chronologically in a JSONL transcript file sitting on your hard drive. It is complete and perfect, the way a court stenographer’s record is complete and perfect. But just as you cannot hand a judge a ten-thousand-page transcript and say “the answer is in there somewhere,” you cannot feed the entire episodic record back into working memory. It won’t fit, and even if it did, you’d go bankrupt on API costs before lunch.
Semantic Memory is distilled knowledge. Not what happened, but what matters. “The user is building a React app.” “The user prefers tabs over spaces.” “The user’s database is PostgreSQL 15.” These are the facts extracted from experience. They are the kind of thing you’d write on an index card and pin to your wall—compact, durable, and useful out of context.
Three types of memory. Three storage mechanisms. One hard problem: how do you keep the expensive conference table clear enough to think, without losing what’s stored in the transcript or the index cards?
This is the problem OpenClaw actually solves.
The Choreography
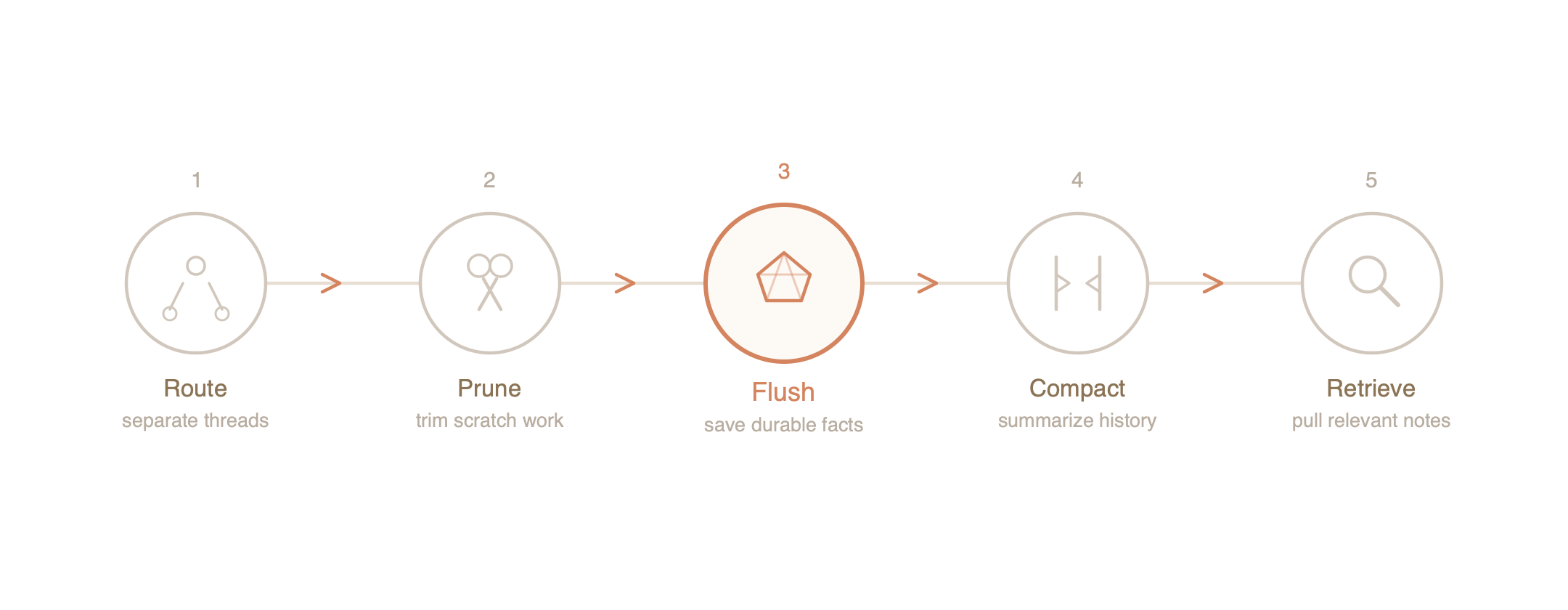
OpenClaw manages memory through a sequence of coordinated operations. Each one is simple. The elegance is in how they compose together.
Routing: One Brain, Many Conversations
Before anything else, OpenClaw solves a problem most people don’t even notice: an AI that talks to you on Slack, Telegram, and email simultaneously needs to know which conversation is which. OpenClaw assigns every thread a unique sessionKey and maintains a separate episodic transcript for each one.
This sounds trivial. It isn’t. Without it, your AI would blend your work debugging a payment system with your friend group’s dinner plans into one incoherent stream of consciousness. Routing is the difference between a filing system and a pile on the floor.
Pruning: The Art of Forgetting Scratch Work
When an AI uses a tool—searches the web, runs code, queries a database—it generates enormous amounts of intermediate output. Raw API responses, stack traces, log dumps. This is scratch work. It was necessary at the time, but five minutes later it’s as useful as yesterday’s scaffolding on a finished building.
Pruning removes this scratch work before the next request is sent to the model. The key detail: it only removes it from working memory. The episodic transcript on disk remains untouched. Nothing is destroyed. The AI simply stops looking at information it no longer needs.
The default time-to-live is five minutes. If a tool result is older than that, its bulky output gets trimmed. The user’s original question and the AI’s final answer are always preserved—only the sprawling middle gets cleared. Think of it as a surgeon removing the gauze and clamps after the operation is done, while keeping the patient notes and the surgical report.
The Memory Flush: Saving Before You Sleep
This is where things get genuinely clever.
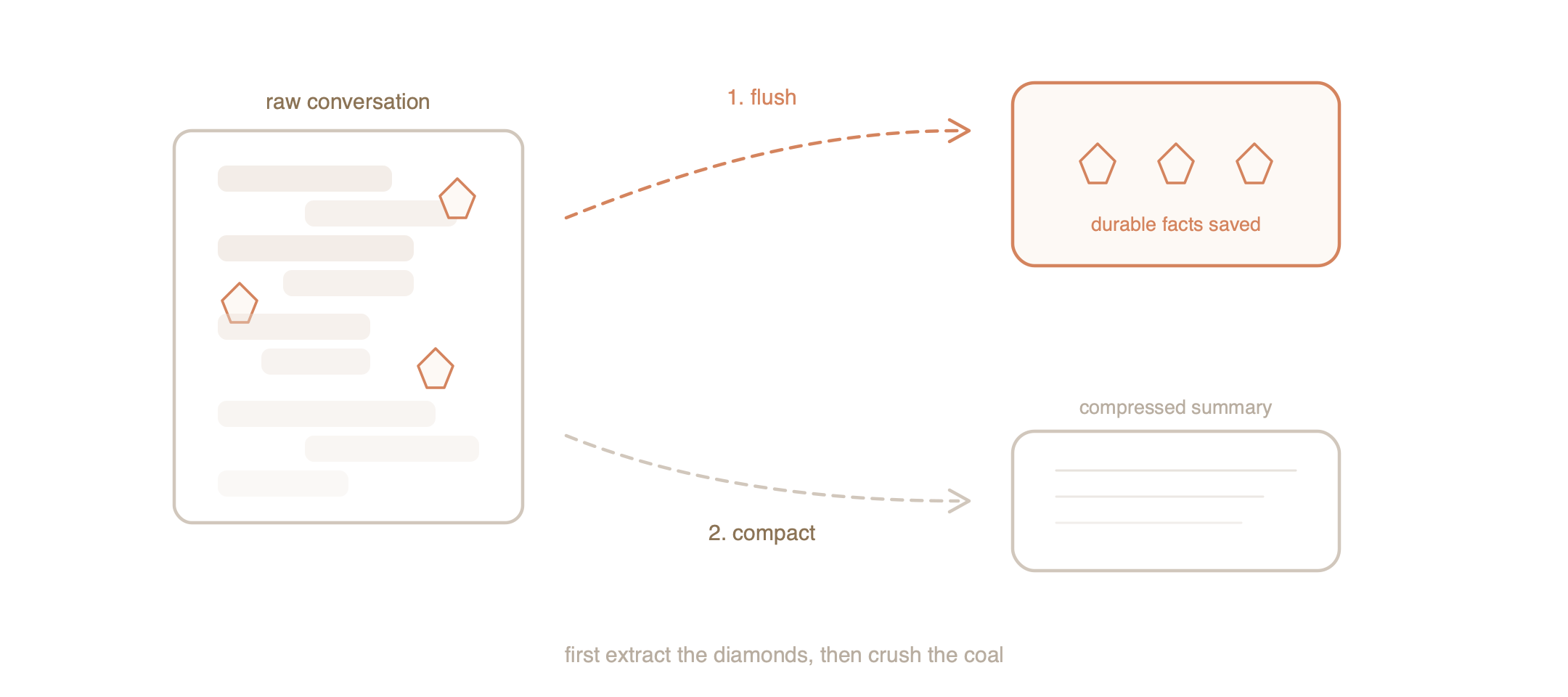
Right before OpenClaw compresses a conversation to save space, it pauses and performs a Memory Flush. It examines the conversation block that is about to be summarized and asks: What durable facts should I extract before this context gets compressed?
The AI then writes those facts—user preferences, project details, important decisions—into storage.
The timing is the critical engineering detail here. The flush happens before compression, guaranteeing that important details are captured in their full fidelity (from the raw transcript) rather than reconstructed from a lossy summary after the fact. First you extract the diamonds. Then you crush the coal.
Compaction: CliffsNotes for Conversations
Once the memory flush has saved the important facts, OpenClaw performs Compaction—replacing the oldest stretch of conversation with a much shorter summary.
A hundred exchanges of greetings, clarifications, and iterative debugging become a single paragraph: “User reported a bug in the payment module. After investigating, we found a race condition in the checkout handler. User approved the fix and asked for tests.”
This summary is written permanently into the episodic transcript. It replaces the raw history in the JSONL file itself. The next time the AI loads this conversation, it reads the compact version. It never re-processes the original verbose exchanges. Compaction isn’t a temporary band-aid—it’s a permanent rewrite of the historical record, like an archivist replacing a shelf of raw documents with a well-written summary volume.
Retrieval: The Right Card at the Right Time
The final piece is retrieval. When you ask a question in a new conversation, the AI doesn’t dump its entire semantic memory into the context window. That would defeat the whole purpose. Instead, it searches—using SQLite full-text search or vector similarity—and pulls only the specific notes relevant to your question.
Ask about your React app, and the note about PostgreSQL stays in the drawer. Ask about the database, and the React details stay put. The conference table only ever holds what’s needed for the current discussion.
Why This Architecture is Deeper Than It Looks
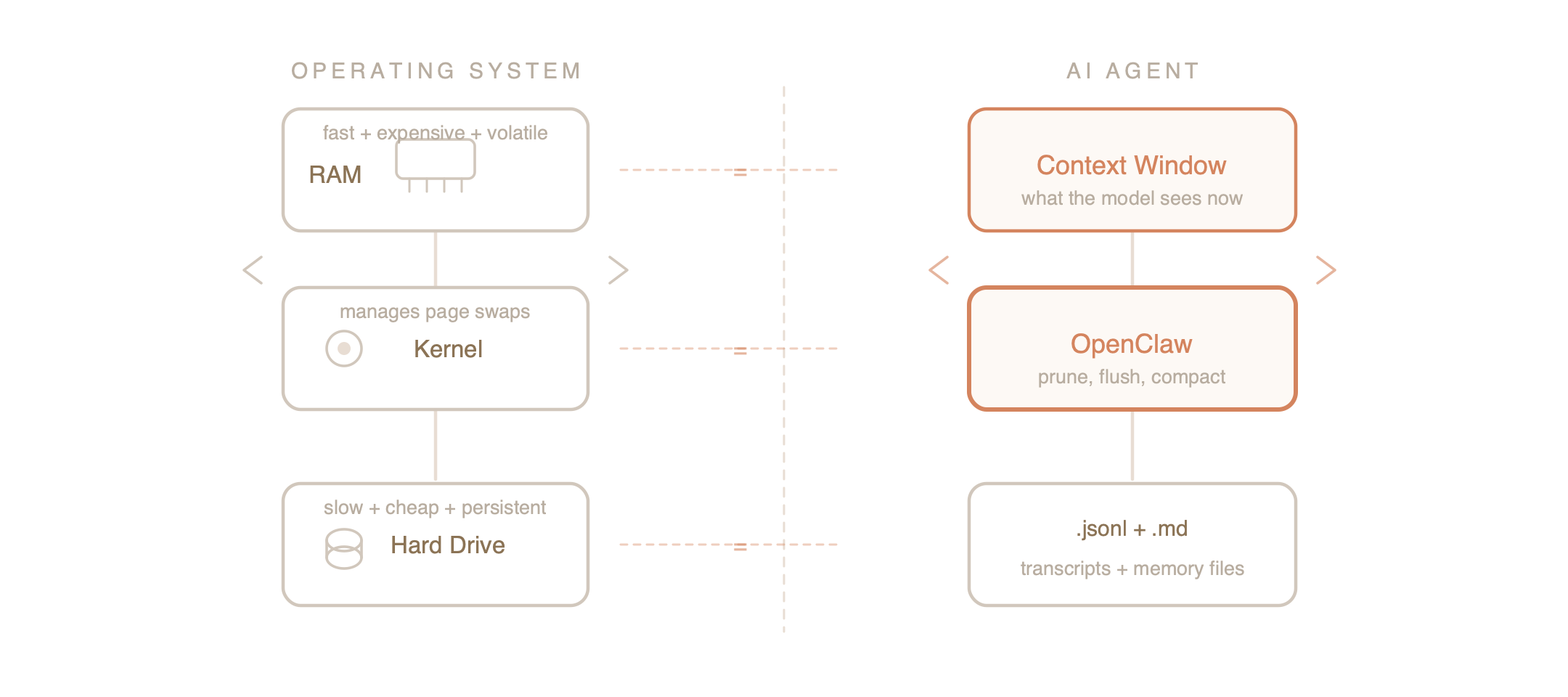
If you step back, you’ll notice something: OpenClaw has independently converged on the structure of an Operating System.
The MemGPT Insight:
Context management is really an OS problem. The context window is RAM (fast, expensive, volatile). The files on disk are the hard drive (slow, cheap, persistent). And OpenClaw acts as the kernel, managing “page swaps” between them. The AI doesn’t need to know the mechanics, just like you don’t think about virtual memory paging when you open a browser tab. The system handles it.
The “Lost in the Middle” Solution:
You might ask: “Why not just use a model with a 1-million-token context window?”
Two reasons. First, cost. Running a 1-million-token prompt for every single “hello” is financially ruinous. Second, and more importantly, attention mechanisms degrade over length. Research shows that LLMs suffer from a “Lost in the Middle” phenomenon—they are excellent at recalling information at the very beginning and very end of a prompt, but they often hallucinate or ignore details buried in the middle.
By aggressively pruning, flushing, and compacting, OpenClaw keeps the context window short and dense. It ensures the model is always looking at a curated, high-signal summary rather than a sprawling, noisy history. It’s not just about saving money; it’s about keeping the AI sharp.
The Whole Picture
Here is OpenClaw’s memory cycle, compressed to its essence:
Route every conversation to its own transcript, so nothing bleeds together.
Prune expired scratch work from working memory, so the model isn’t buried in stale logs.
Flush durable facts to storage, so knowledge survives compression.
Compact old conversation history into summaries, so the transcript stays manageable.
Retrieve relevant notes on demand, so the model always has what it needs without carrying what it doesn’t.
Each step is simple. Together, they create something that feels like an AI with a genuine memory—one that remembers your project, your preferences, and your past decisions, without hemorrhaging tokens.
The smartest amnesia patient in the world, finally given a notebook and taught to use it.
Reference