


Morning, CEO!
A startup called LMArena announced they raised $150 million at a $1.7 billion valuation.

If you’re keeping score at home, that is a unicorn status for a website that is, essentially, a “Hot or Not” for chatbots.
They don’t build the models. They don’t sell the chat apps. They are the referee.
And usually, the referee is the guy getting yelled at by drunk dads at a Little League game, not the guy walking away with a billion-dollar check.
So, how did a tiny UC Berkeley research project turn into a unicorn in roughly the time it takes me to decide what to make for dinner?
Let’s steal their playbook.
1. The “Memorizing the Eye Chart” Problem
Back in the dark ages (2023), if you wanted to know if an AI was smart, you gave it a standardized test.
We called them benchmarks. They were the SATs for robots. Multiple choice. Math. History. Coding.
The problem is that AI models are professional cheaters.
Imagine a student who refuses to learn biology but manages to memorize the answer key to the final exam.
Question 1: B.
Question 2: A.
The student gets 100%. The teacher thinks the student is the next Doogie Howser. Then you ask the student to perform open-heart surgery, and well... it’s messy.
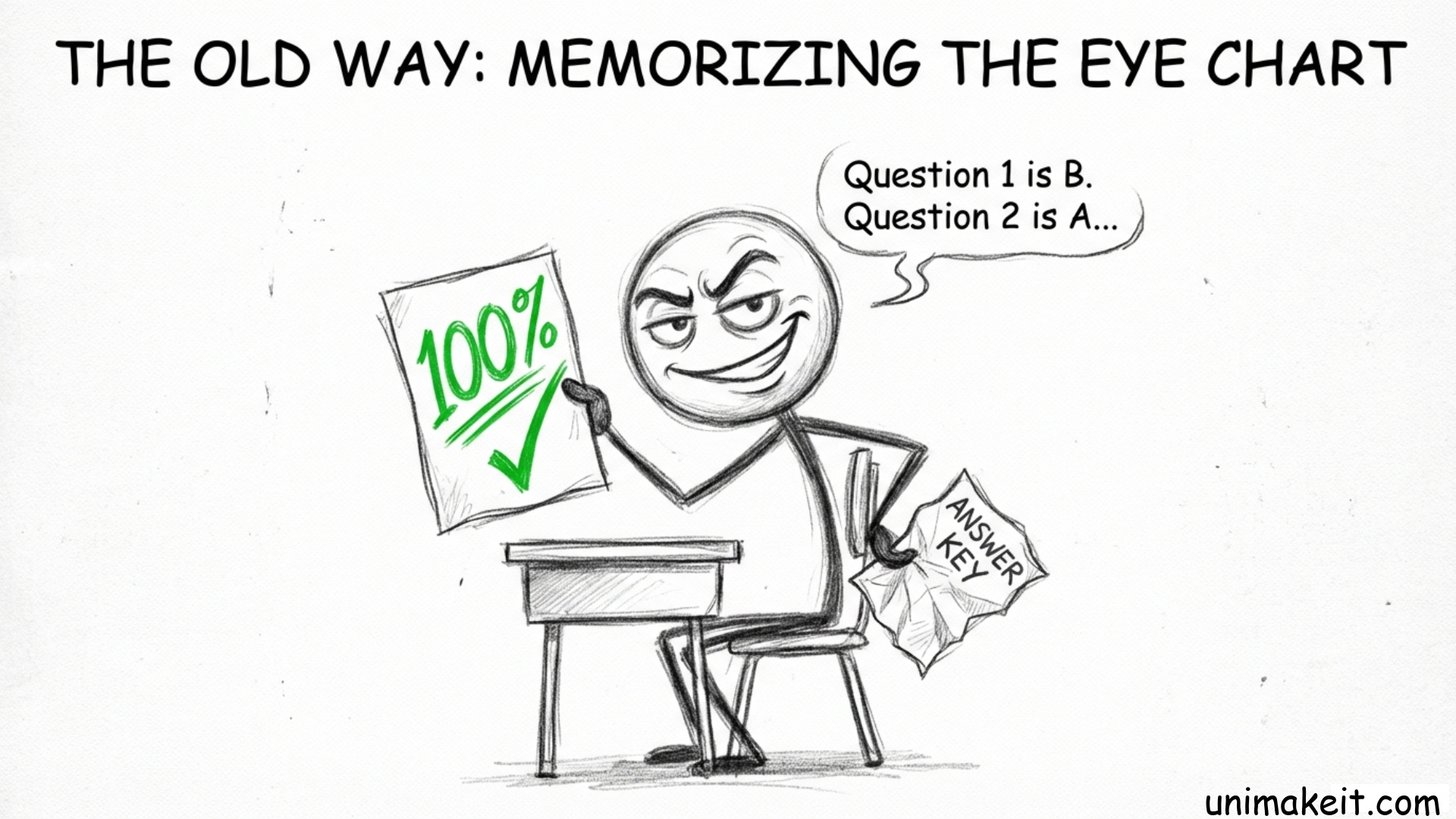
In the AI world, we call this overfitting.
Because these models are trained on the entire internet, they had often already seen the test questions during training. They weren’t solving the problem; they were remembering the answer.
So, every company started claiming they were “Smarter than GPT-4.” But when I used them to debug my Python script, they hallucinated a library that didn’t exist.
LMArena realized the “Exam” was broken. So they pivoted to the “Thunderdome.”

They built a “Blind Test” arena.
You type a prompt. Two anonymous models generate answers. You vote for the winner.
You can’t cheat on this test because the test is you. The test is 5 million humans asking 60 million weird, messy, unpredictable questions every month.
When the standard metrics (exams) become commodities that everyone can game, the only valuable metric left is raw, subjective user preference. LMArena cornered the market on “what humans actually like.”

2. The “Nano Banana” Pivot
If LMArena was just a leaderboard, it would be a cool Wikipedia page. Not a billion-dollar business.
The real money—the “I’m buying a yacht” money—comes from a boring sounding thing called Routing.

Let me explain with a banana.
A while back, a mysterious model appeared on the leaderboard under the code name “Nano Banana.” It started crushing everyone.
It turned out to be a small, efficient preview model from a major lab.
This highlighted a massive inefficiency.
Right now, most companies are lazy. They pay for the biggest, smartest, most expensive model (like GPT-5.2 or Claude 4.5 Opus) for everything.
It’s like hiring Einstein to do your taxes.
Sure, he can do them. But he costs a fortune. Meanwhile, there’s a guy named Bob (a smaller model) who is actually better at taxes than Einstein, and he costs $5.

But how do you know when to use Einstein and when to use Bob?
LMArena knows.
They have millions of data points on exactly which models are good at exactly which questions.
So they built a product called “Prompt to Leaderboard.” It’s an API. When you send a query, LMArena instantly analyzes it and says:
“Okay, this is a basic summary task. For this, the cheap open-source model is 99% as good as the expensive model. Route it to the cheap one.”
Boom. You just saved 50% on your bill.
They aren’t selling the ranking. They are selling efficiency. In an Agency of One, your value often isn’t doing the work; it’s knowing exactly which tool (or subcontractor) can do the work cheapest and fastest without sacrificing quality.
3. The Death of the “Average” Human
Here is the existential part.
Right now, the leaderboard tells you what the “average” human likes.
But the average human doesn’t exist.
If I ask an AI to “Write a function to sort a list,” I want a dry, efficient code block. I’m an engineer. I don’t want small talk.
If a beginner asks the same question, they want a long, patient explanation with analogies about sorting laundry.
If the AI gives the dry code block to the beginner, the beginner votes “Bad.”
If the AI gives the long explanation to me, I vote “Bad” (and roll my eyes).
Subjectivity is a mess.
LMArena realized that a single “King of AI” is a myth.
So, they are moving toward Personalized Evals.
They want to look at your history and say: “Okay, Hannah likes her answers funny, short, and slightly cynical. She hates emojis. She loves analogies.”
Then, they route your questions to the model that fits your specific brain.
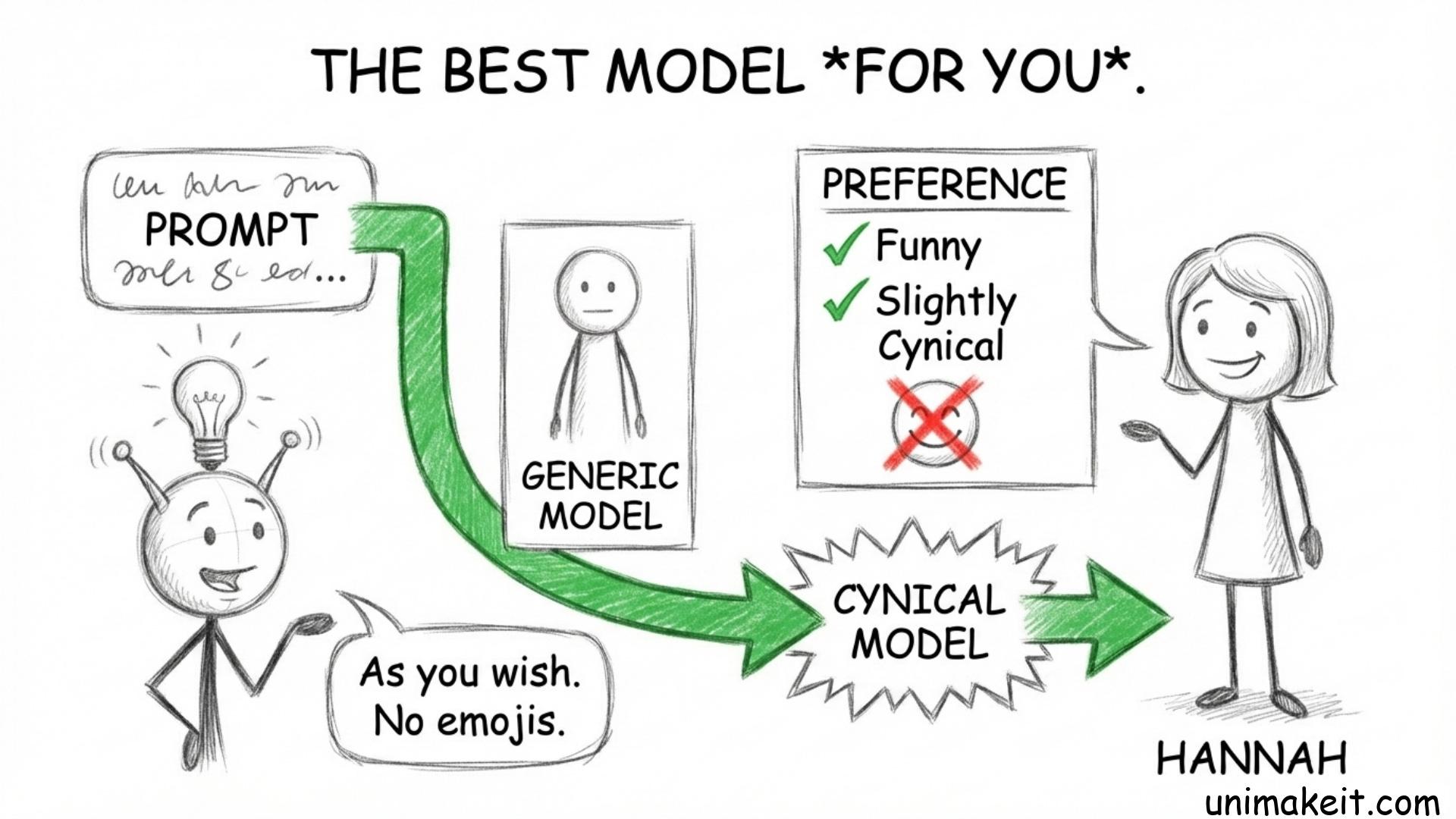
The future isn’t about the “best” model. It’s about the best model for the specific user context. If you can map your client’s specific context better than they can, you win.
The Punchline
We spent the last few years obsessing over who would build the “God Model.”
But while the giants were fighting over who could build the biggest brain, a bunch of students at Berkeley realized something smarter:
It doesn’t matter how big the brain is if it doesn’t make the human happy.
LMArena didn’t win by building AI. They won by building a mirror that reflects what we actually want.

And it turns out, knowing what humans want is worth exactly $1.7 billion.

Links:
https://x.com/ml_angelopoulos
https://lmarena.ai
[State of Evals] LMArena’s $1.7B Vision — Anastasios Angelopoulos, LMArena
https://www.theinformation.com/articles/ai-evaluation-startup-lmarena-valued-1-7-billion-new-funding-round?rc=epv9gi
